
Elasticsearch uses a special data structure called "Inverted index" for very fast full-text searches. An inverted index consists of a list of all the unique words that appear in any document, and for each word, a list of the documents in which it appears. Inverted index is created from document created in elasticsearch. Inverted index is created using process called analysis (tokenisation and Filterization).
Text Analysis for indexing and searching (Inverted index creation):
Analysis process is key step in creating inverted index in shards. Analysis is not only performed while creating document, it's also performed while retrieving or querying(GET) document. Below diagram shows how analysis is performed while indexing.
Document text is tokenised and filtered by Analyzer (analyzer is setup while defining Index structure). After processing it created inverted index which is stored in shard's segment. Consider two document text below for analysis.
Lets assume we are interested in comment fields of document. We have two text to consider for analysis.
1. The thin lifeguard was swimming in the lake
2. Swimmers race with the skinny lifeguard in lake
Tokenisation: To create an inverted index, we first split the comment of each document into separate words (which we call terms, or tokens), create a sorted list of all the unique terms, and then list in which document each term appears.
i.e: Split each doc comment text with respect to space and we get following tokens and its presence in doc.
Filtering: After tokenisation filter is applied on these. Filters are such as:
Text analysis while retrieving and querying document: When GET command is executed for retrieving document analyzer is used same as while indexing (described above). Below diagram shows match string "the thin" is passed through analyser and search is performed on "thin"- stopping word "the" is removed.
 Reference : Index time analysis and search time analysis details
Reference : Index time analysis and search time analysis details
In this post we will see how inverted index are created and how it is stored in shards which later used for searching documents.
Document to Searchable Index: When a document is created in elasticsearch(ELS). It goes through various phases and becomes eligible to searching. Below diagram gives overview of the same.
 |
| Complete cycle of Inverted index creation from document : An immutable shard's segment |
- Client issues command for creating document in ELS. Refer this and this posts for more details, how to create document in ELS.
- Once document is created in ELS, it goes through analysis phase where documents are tokenised and normalised (stemming, synonyms detected and remove stop words). Refer this for more details about Inverted index creation.
- For a given document, inverted index is created and stored in temporary buffer till it become full. Once buffer is full, it is flushed into segments.
- A segment is smallest logical unit. Shard can be viewed as collection of segments. Segments are filled with flushed inverted index.
- Once a working segment is filled completely with inverted index, shards becomes eligible for searching. Segments created are immutable - collection of immutable inverted index.
Text Analysis for indexing and searching (Inverted index creation):
Analysis process is key step in creating inverted index in shards. Analysis is not only performed while creating document, it's also performed while retrieving or querying(GET) document. Below diagram shows how analysis is performed while indexing.
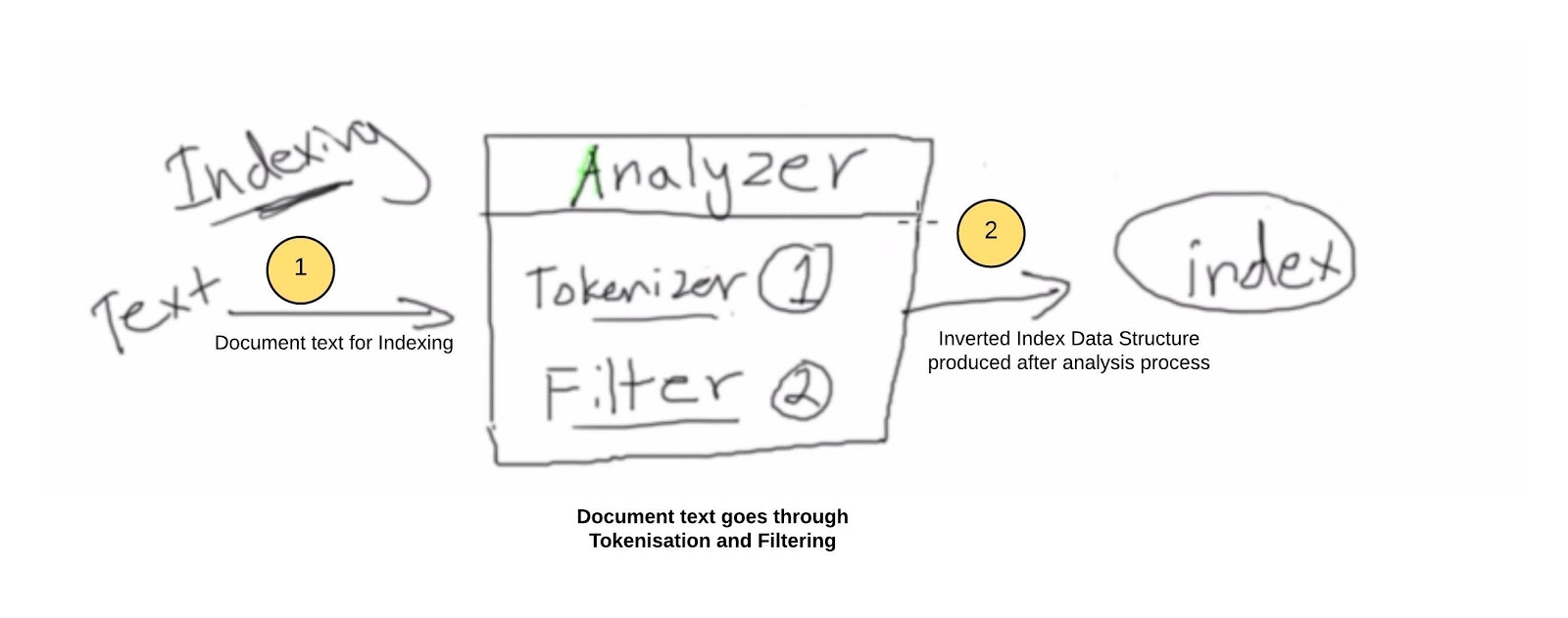 |
| Analysis phase : Indexing of document |
{
"name" : "Nikhil",
"id": "zytham",
"comment" : "The thin lifeguard was swimming in the lake"
"date" : "2018-02-12"
}
{
"name" : "Ranjan",
"id": "nranjan",
"comment" : "Swimmers race with the skinny lifeguard in lake"
"date" : "2018-02-12"
}
Lets assume we are interested in comment fields of document. We have two text to consider for analysis.
1. The thin lifeguard was swimming in the lake
2. Swimmers race with the skinny lifeguard in lake
Tokenisation: To create an inverted index, we first split the comment of each document into separate words (which we call terms, or tokens), create a sorted list of all the unique terms, and then list in which document each term appears.
i.e: Split each doc comment text with respect to space and we get following tokens and its presence in doc.
| Token | Present in Document |
|---|---|
| Swimmers | 2 |
| The | 1 |
| in | 1,2 |
| lifeguard | 1,2 |
| lake | 1,2 |
| race | 2 |
| skinny | 2 |
| swimming | 2 |
| the | 1,2 |
| thin | 1 |
| was | 1 |
| with | 1 |
- Removing stop words (the, in, etc. of english word)
- Lowercasing (To make search case insensitive)
- stemming (swimming to swim)
- synonymous ( thin == skinny )
Elasticsearch provides pre-builtin wide range of analysers which can be used in any index without further configuration. Here is list of elasticsearch builtin analyzer.
Text analysis while retrieving and querying document: When GET command is executed for retrieving document analyzer is used same as while indexing (described above). Below diagram shows match string "the thin" is passed through analyser and search is performed on "thin"- stopping word "the" is removed.

Tags:
Elasticsearch
Thank you for this intro!
ReplyDeleteIt was helpful for me
it's okay bro
Deletemany ways to store your data like you can save your data online and benefits not burden your hard disk.
ReplyDeleteĐặt vé tại Aivivu, tham khảo
ReplyDeletevé máy bay đi Mỹ giá rẻ
hướng dẫn đi máy bay từ mỹ về việt nam
khi nào có chuyến bay từ canada về việt nam
dat ve may bay tu han quoc ve viet nam
Hi! Would you mind if I share your blog with my zynga group?
ReplyDeleteThere's a lot of folks that I think would really enjoy your content.
Please let me know. Many thanks
Feel free to surf to my webpage: 휴게텔
OMG~!!!!! into your huge blog for almost the last hour.|I think the admin of this website is really working a lot.|Thanks for posting this up on your blog.|I am surprised at how slow your article loaded on my lap top.|Thank you for writing these great website.|The shorter response is that I don't know very much about the subject, a longer answer is that I'm going to understand what I'm able to Thanks for this post. I found it to be very encouraging. I really learned a lot because of you.오피사이트
ReplyDeleteThe use of China Metalized polyester film suppliers films makes it simple to protect goods without taking up an excessive amount of space. Importantly, they are also made from components that are not poisonous to the environment, which is important for environmental reasons. Additionally, they are recycling and reusing materials.
ReplyDeleteNice blog thanks for posting.
ReplyDeleteThis explanation of how Elasticsearch uses an inverted index for fast full-text searches is very helpful.
ReplyDelete